Statistically-based methodology for revealing real contagion trends and correcting delay-induced errors in the assessment of COVID-19 pandemic
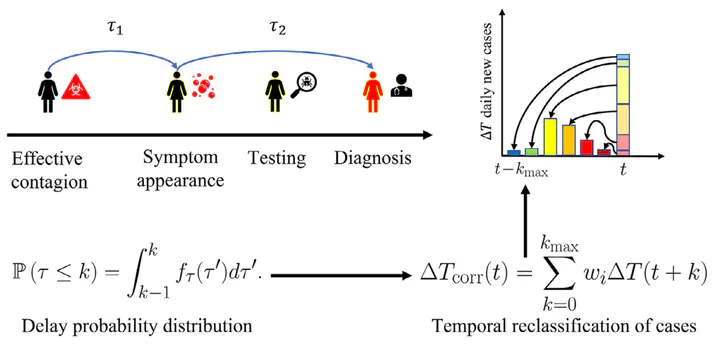 Image credit: Seba Contreras
Image credit: Seba Contreras
Abstract
COVID-19 pandemic has reshaped our world in a timescale much shorter than what we can understand. Particularities of SARS-CoV-2, such as its persistence in surfaces and the lack of a curative treatment or vaccine against COVID-19, have pushed authorities to apply restrictive policies to control its spreading. As data drove most of the decisions made in this global contingency, their quality is a critical variable for decision-making actors, and therefore should be carefully curated. In this work, we analyze the sources of error in typically reported epidemiological variables and usual tests used for diagnosis, and their impact on our understanding of COVID-19 spreading dynamics. We address the existence of different delays in the report of new cases, induced by the incubation time of the virus and testing-diagnosis time gaps, and other error sources related to the sensitivity/specificity of the tests used to diagnose COVID-19. Using a statistically-based algorithm, we perform a temporal reclassification of cases to avoid delay-induced errors, building up new epidemiologic curves centered in the day where the contagion effectively occurred. We also statistically enhance the robustness behind the discharge/recovery clinical criteria in the absence of a direct test, which is typically the case of non-first world countries, where the limited testing capabilities are fully dedicated to the evaluation of new cases. Finally, we applied our methodology to assess the evolution of the pandemic in Chile through the Effective Reproduction Number Rt, identifying different moments in which data was misleading governmental actions. In doing so, we aim to raise public awareness of the need for proper data reporting and processing protocols for epidemiological modelling and predictions.
Seba Contreras
Postdoctoral Researcher in Physics of Disease Spread
My research interests include infectious diseases, complex systems and mathematical modelling.